Using Uproot¶
Import Needed Functions¶
To create our query and send it to the backend, we need a few functions and classes. Let’s import them.
from servicex import deliver, query, dataset
import awkward as ak
import matplotlib.pyplot as plt
The dataset and query objects are used to define our request and are then packaged into a spec. The deliver function sends the spec to the backend. We also import one of our analysis utilities, to_awk, which processes the data returned from ServiceX.
from servicex_analysis_utils import to_awk
Setting Up Our Dataset¶
Before we build our query and spec, we need to specify our dataset. ServiceX supports multiple types of datasets, but all types must be publicly accessible or available to all ATLAS users. More information about supported dataset locations can be found in our full documentation.
For this tutorial, we’ll use an NTuple stored in Rucio. If you already have an NTuple available in Rucio, you can use it for this tutorial, though the tree and branch names may differ.
ntuple_dataset = dataset.Rucio("user.acordeir:michigan-tutorial.displaced-signal.root")
If the dataset is located in EOS instead of rucio it can be define like this:
ntuple_dataset = dataset.FileList(["root://eospublic.cern.ch//eos/..."])
Building Our Query¶
The second thing needed to construct our spec is the query. Here we define the data we would like selected and we can also define cuts. For uproot-raw queries the treename needs to be define, then the branches selected, and then finally cuts can be made.
uproot_raw_query = query.UprootRaw([{
'treename':'reco',
'filter_name':
["truth_alp_decayVtxX",
"truth_alp_decayVtxY",
"truth_alp_pt",
"truth_alp_eta",
"jet_EMFrac_NOSYS",
"jet_pt_NOSYS"],
'cut':
'(num(jet_pt_NOSYS)<2) & any((truth_alp_pt>20) & (abs(truth_alp_eta)<0.8))'
}]
)
Building The Spec¶
The hard work has been done and now we just need to package everything up in a spec object before we pass it to the deliver. Here is how that is done for this example:
spec_uproot_raw = {
'Sample': [{
'Name': 'UprootRawExample',
'Dataset': ntuple_dataset,
'Query': uproot_raw_query
}]
}
Deliver The Spec¶
Now that we have a spec setup we can deliver it to the backend.
results_uproot_raw=deliver(spec_uproot_raw)
The deliver function sends the query to the backend where the transform is processed. Then the processed files are downloaded to the client (in a configured directory). The variable results_uproot_raw has a list of those files. This list is what can be used to start the analysis of those files.
Analyze The Data¶
We can load that list of files that the deliver function returned into akward using the to_awk function. Then we can do a standard Histogram workflow to finally get our histogram!
arr = to_awk(results_uproot_raw)["UprootRawExample"]
# compute displacement
displacement = (arr["truth_alp_decayVtxX"]**2 +
arr["truth_alp_decayVtxY"]**2)**0.5
# flatten the awkward arrays
emfrac = ak.flatten(arr["jet_EMFrac_NOSYS"])
disp = ak.flatten(displacement)
# set up side-by-side subplots
fig, axes = plt.subplots(1, 2, figsize=(9, 4))
# EM fraction
axes[0].hist(emfrac, bins=50, range=[0,1] )
axes[0].set_title(15 Minute Challenge: Jet EM Fraction")
axes[0].set_xlabel("EM Fraction")
axes[0].set_ylabel("Counts")
# displacement
axes[1].hist(disp, bins=50, range=[0,5000], color="g")
axes[1].set_title(15 Minute Challenge: Decay Vertex Displacement")
axes[1].set_xlabel("Displacement in x-y (mm)")
axes[1].set_ylabel("Counts")
plt.tight_layout()
plt.show()
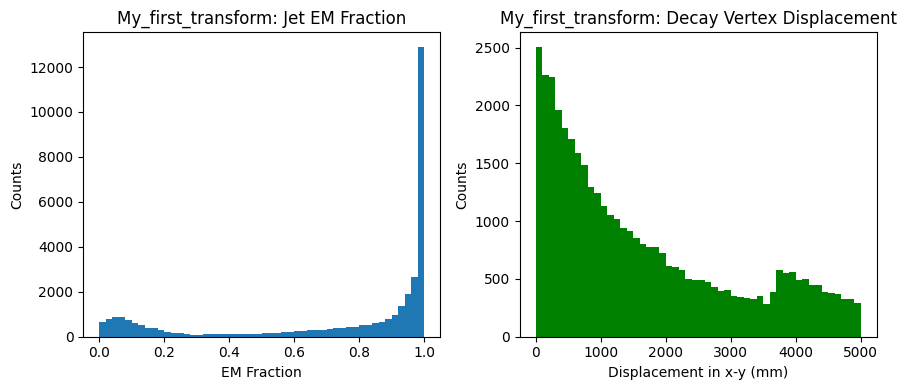
The result from this code is the following plots: